스프링 트랜잭션 AOP가 등장하기 전 이전의 문제점들을 정리해보고 어떠한 매커니즘으로 동작하는지 정리하고자 한다.
그 과정에서 등장하는 스레드 로컬을 사용한 트랜잭션 동기화 매니저, 템플릿 콜백 패턴, 스프링 AOP 등의 기술과 자세한 동작 방식은 추후 자세히 정리해보도록 할 것이다.
지금은 트랜잭션 AOP가 등장하기까지의 배경 및 변천사를 중점적으로 정리해보겠다.
문제의 시작
기본적으로 트랜잭션의 시작과 끝은 비지니스 로직이 있는 Sevice 계층에서 시작하는 것이 좋다.
예를 들어 비지니스 로직 중 계좌의 돈을 차감하고 또 계좌의 돈을 추가하는 두개의 기능이 있는데, 예외로 인해 일부만 commit 되고 일부는 rollback되면 어떨까?
심각한 데이터 적합성 등 문제가 발생할 것이다.
그러므로 비지니스 로직에서 수행하는 작업들은 함께 커밋되거나 함께 롤백 되어야한다.
우선 코드를 통해 문제점을 살펴보도록 하자.
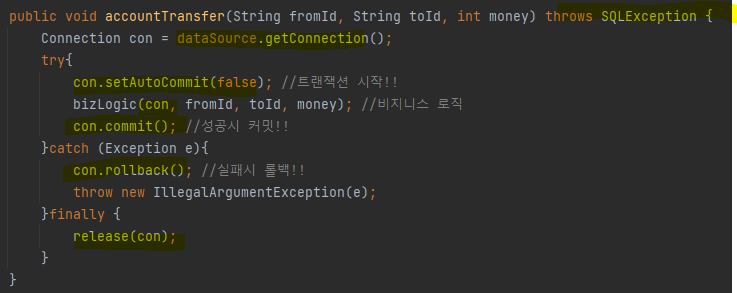
해당 로직은 간단히 입금, 출금에 관한 비지니스 로직이다. 해당 코드는 아래와 같은 문제점이 있다.
- 서비스 계층이 특정 기술(JDBC,JPA 등)의 의존적이다.
- 현재 코드에서 사용한 DataSource, 트랜잭션 시작, 커밋, 롤백 등은 JDBC의 기술이다.
- 만약 JPA를 사용한다면 JPA에는 트랜잭션을 얻기 위해 영속성 컨텍스트를 사용하기 때문에, 코드 수정이 불가피하다.
- 즉 서비스 계층에 특정 기술이 누수된 문제점이 발생한다.
- 트랜잭션 동기화 문제
- 서비스 계층에서 트랜잭션의 시작과 끝이 이루어져야 하기때문에, 즉 같은 트랜잭션을 유지하기 위해 커넥션(con)을 매번 repository로 넘겨주어야 된다.
- 만약 트랜잭션이 필요없는 상황과 필요한 상황이 발생한다면 같은 기능이지만, 커넥션 파라미터로 유무로 분리해서 만들어놓아야 할 것이다.
- 트랜잭션의 반복 코드 문제
- 트랜잭션을 사용하기 위해서 트랜잭션 시작, 커밋, 롤백, 리소스 정리와 같이 매번 동일한 코드가 반복된다.
- 예외 누수
- 현재 repository 계층의 JDBC 구현 기술의 예외(SQLException)가 서비스 계층으로 전파된다.
- 사용 기술이 바뀐다면, 기술에 맞는 예외로 항상 수정해야할 것이다.
그러니깐 매번 기술(JDBC, JPA 등)이 바뀔때마다 트랜잭션 코드 변경 문제가 발생하는 거니깐, 특정 기술에 의존하지 않게 추상화하면 되는거 아니야?
그리고 같은 트랜잭션을 유지하기 위해서, 즉 커넥션 동기화를 위해서 별도로 커넥션을 보관하고 거기서 꺼내서 사용하면 되는거 아니야?
맞다! 이러한 기능들을 스프링의 트랜잭션 매니저, 트랜잭션 동기화 매니저가 이를 해결해준다.
PlatformTransactionManager(스프링의 트랜잭션 매니저)
스프링은 트랜잭션 추상화를 위해서 PlatformTransactionManager 인터페이스를 제공해준다.
해당 인터페이스에 대해 JDBC, JPA, 하이버네이트 등 마다 구현체가 존재하게 된다.
간단히 내부 메서드 종류를 보게 되면, 기본적인 필요한 메서드만 있는 것을 볼 수 있다.



참고로 getTranscation 같은 경우에는, 트랜잭션 참여, 전파 등의 다양한 트랜잭션 속성이 존재한다.
또한, 스프링은 트랜잭션 리소스 동기화를 위해 TranscationSynchroizationManger 클래스(트랜잭션 동기화 매니저)를 제공해준다.
트랜잭션의 시작과 끝까지 같은 데이터베이스 커넥션을 유지하도록 도와주고, 스레드 로컬을 사용하여 멀티 쓰레드 상황에서 안전하게 트랜잭션 동기화를 할 수 있도록 해준다. (이는 다음에 정리해보도록 하겠다.)
그럼 스프링의 트랜잭션 매니저를 사용한 코드를 보도록 하자.
Repository

현재 Repository 계층은 순수 JDBC를 이용하여 구현된 상태이다. 이를 JPA, Spring Data JPA 등의 기슬로 바꾸는 것은 데이터 접근 기술의 대한 문제이다. 지금은 트랜잭션에 좀 더 초점을 맞추도록 하겠다.
DataSourceUtils.getConnection()을 하게 되면 트랜잭션 동기화 매니저가 관리하는 커넥션이 있으면 해당 커넥션을 반환해주게 된다. 만약 없을 시 새로운 커넥션을 생성해서 반환해주게 된다.
DataSourceUtils.releaseConnetion()은 커넥션을 닫는 것이 아니라 사용을 마친 커넥션을 트랜잭션 동기화 매니저에게 반납해주게 된다. 만약 관리하는 트랜잭션이 없다면 해당 커넥션을 닫게 된다.
Service
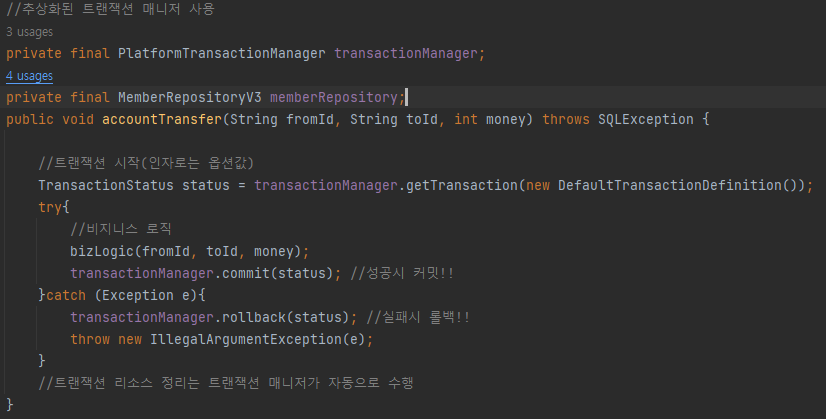
PlatformTransactionManager 구현체로 사용할 트랜잭션 매니저(JDBC,JPA 등)를 주입 받게 되고,
공통된 인터페이스 메서드를 통해 트랜잭션 획득, 커밋, 롤백이 수행되게 된다.
참고로, new DefaultTransactionDefinition()을 통해 트랜잭션 속성을 지정할 수 있다.
또한, 트랜잭션 종료 후 커넥션 리소스를 자동으로 정리해준다.
만약 직접 커넥션 생성 방식(DriverManageDataSource)을 사용한다면 해당 커넥션을 끊게 되고,
커넥션 풀(HikariDataSource)을 사용한다면 커넥션 풀로 반환해주게 된다.
Test

테스트에서 트랜잭션 매니저로 JDBC(DriverSourceTranscationManager)를 사용했고,
이 밖에도 JPA(JpaTranscationManager), Hibernate(HibernateTranscationManager) 등의 원하는 트랜잭션 매니저 구현체를 주입하면 된다.
또한, 트랜잭션 매니저는 DataSource를 통해 커넥션을 생성하기 때문에 DataSource가 필요하다.(여기선 DriverManager 방식, 즉 커넥션 직접 생성 방식을 사용함)
그럼 전체적인 동작 흐름을 정리해보겠다.
- 서비스 계층에서 트랜잭션 시작 호출(PlatformTransactionManager 을 이용했으므로 기술의 관계없이 일관된 트랜잭션 기능 사용가능)
- 트랜잭션 매니저(PlatformTransactionManager)는 내부에서 DataSource를 이용하여 커넥션을 생성한다.
- 수동 커밋 모드로 전환 후 트랜잭션을 시작한 뒤, 해당 커넥션을 트랜잭션 동기화 매니저에 보관한다.
- 비지니스 로직을 실행하며 repository의 메서드들을 호출하고, 해당 리포지토리 메서드들은 DataSourceUtils.getConnection()을 통해 트랜잭션 동기화 매니저에 보관된 커넥션을 가져온다. (즉 같은 커넥션을 사용하니 같은 트랜잭션으로 유지된다.)
- 해당 커넥션으로 SQL문 실행
- 비지니스 로직이 종료되고 트랜잭션 종료를 위해, 트랜잭션 동기화 매니저를 통해 동기화된 커넥션을 획득한다.
- 획득한 트랜잭션을 커밋 또는 롤백을 진행하고, 전체 리소스를 정리한다.
- DriverManageDataSource 방식 사용 시 커넥션 종료
- HikariDataSource 방식 사용 시 커넥션 풀의 반납
트랜잭션 매니저를 통해 트랜잭션 추상화 및 동기화 문제를 해결할 수 있었다.
하지만 트랜잭션과 관련된 반복 코드 문제(트랜잭션 시작, 커밋, 롤백)가 여전히 남아있다.
이를 스프링이 템플릿 콜백 패턴이 적용된 TransactionTemplate 클래스를 통해 이를 해결해주게 된다.
TransactionTemplate(트랜잭션 템플릿)
템플릿 콜백 패턴을 적용하려면 템플릿을 제공하는 클래스를 작성해야 하는데, 스프링은 TransactionTemplate 라는 템플릿 클래스를 제공해준다. (텔플릿 콜백 패턴은 추후 자세히 공부 후 정리해보겠다.)
이 스프링 트랜잭션 템플릿 클래스는 트랜잭션 시작, 커밋, 롤백을 자동으로 수행해주는 기능을 한다.
코드를 통해 살펴보도록 하자
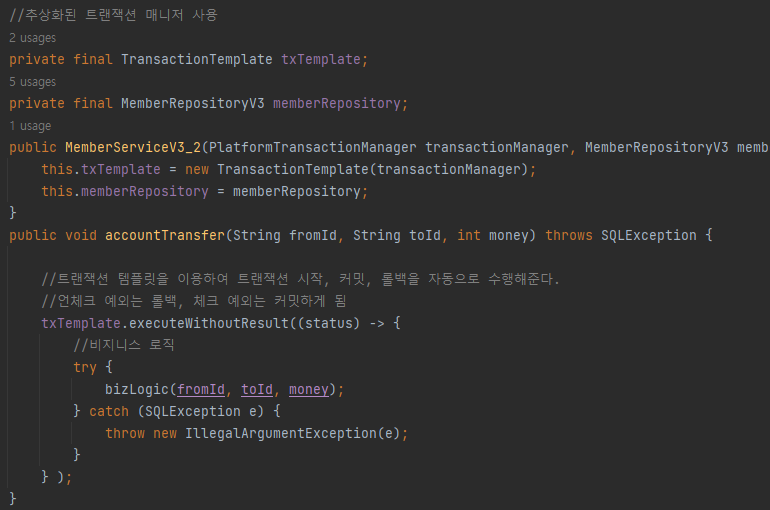
TransactionTemplate(트랜잭션 템플릿)은 앞서 설명한 PlatformTransactionManager(트랜잭션 매니저)를 파리미터로 필요요 한다.
execute()(반환 값 있음), executeWithoutResult()(반환값 없음)의 간단히 두가지 메서드를 지원한다.
보다시피 이전에 트랜잭션과 관련된 반복코드가 사라진 것을 볼 수 있다.
(참고로 언체크 예외 발생시 롤백, 체크 예외 발생시 커밋을 수행함)
하지만 여전히 비지니스 로직에 트랜잭션 처리와 관련된 로직이 남아있다.
비지니스 로직에는 진짜 비지니스 로직만 존재하고 트랜잭션 로직은 별도로 분리될 순 없을까?
이를 스프링은 AOP기술을 사용한, 프록시 객체를 통해 이를 해결해준다.
@Transcational(스프링 트랜잭션 AOP)
트랜잭션 AOP는 스프링의 AOP 기술을 사용해 트랜잭션 관련 로직을 프록시 객체로 대신 수행하게 된다.
즉 개발자는, service 계층에 트랜잭션 AOP 가 적용된 트랜잭션 프록시 객체 실제 의존성 주입 받게되고 이를 사용하게 된다.
이 트랜잭션 프록시 객체는 내부적으로 트랜잭션 매니저와 트랜잭션 동기화 매니저를 마찬가지로 사용하고, 실제 service의 비지니스 로직을 호출하여 동작하게 된다.(앞서 설명한 트랜잭션 매니저의 매커니즘과 동일하게 동작한다.)
코드로 살펴보도록 하자.

순수 비지니스 로직만 남게 되는것을 볼 수 있다.
@Transcational 어노테이션 만 붙히면, 스프링 AOP가 서비스 계층의 프록시 객체를 생성하게 된다.
또한, 스프링 컨테이너에서 빈으로 등록된 트랜잭션 매니저를 사용하여 트랜잭션 관련 기능을 프록시 객체가 대신 수행해주게 된다.
(참고로 트랜잭션 매니저와 데이터소스는 application.properties or yml 를 통해 쉽게 스프링 빈으로 자동 등록이 가능하다.)
간단히 아래와 같이 프록시 객체가 실제 생성된것을 확인할 수 있다.
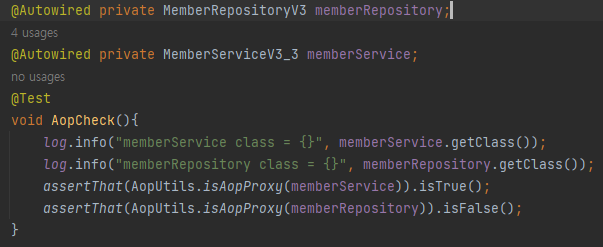

@Transcational 어노테이션을 서비스 계층에만 선언했고, 실제 해당 서비스 클래스는 프록시 객체로 생성된 것을 볼 수 있다.
스프링 AOP와 관련된 기술을 중요하다고 생각이 들어, 공부 후 따로 정리해봐야겠다. 😂
지금까지 앞서 도입부에서 말한 4가지 문제점 중 1,2,3 문제는 해결될 수 있었다.
하지만 아직 4.예외 누수의 문제점이 남아있다. 현재 Repository에서는 JDBC 기술을 사용하기 때문에 SQLException예외가 발생했다.
이 예외는 체크 예외이기 때문에 반드시 해결(try~catch)하거나 밖으로 던져(Throws)야 한다. 그러다 보니 Service 계층에도 해당 예외를 처리할 수 없기 때문에 Throws 하게 되고 특정 기술(JDBC)의 예외에 의존하게 되는 문제가 발생한다.
이러한 문제를 스프링이 어떻게 해결했는지 다음 포스터에서 살펴보도록 하자.
자료
- 김영한 스프링 DB 1편-데이터 접근 핵심 원리
'JAVA > Spring & Java 학습 기록' 카테고리의 다른 글
| 동시성 이슈와 데드락 문제를 비관적 락를 이용해 해결하다. (0) | 2023.06.28 |
|---|---|
| 스프링의 예외 누수 문제 해결 변천사 (0) | 2023.06.25 |
| 스프링 인터셉터를 이용한 권한 검증 분리하기 (0) | 2023.06.14 |
| 트랜잭션 이해와 락 (0) | 2023.05.24 |
| 커넥션 풀과 데이터소스 (0) | 2023.05.20 |



